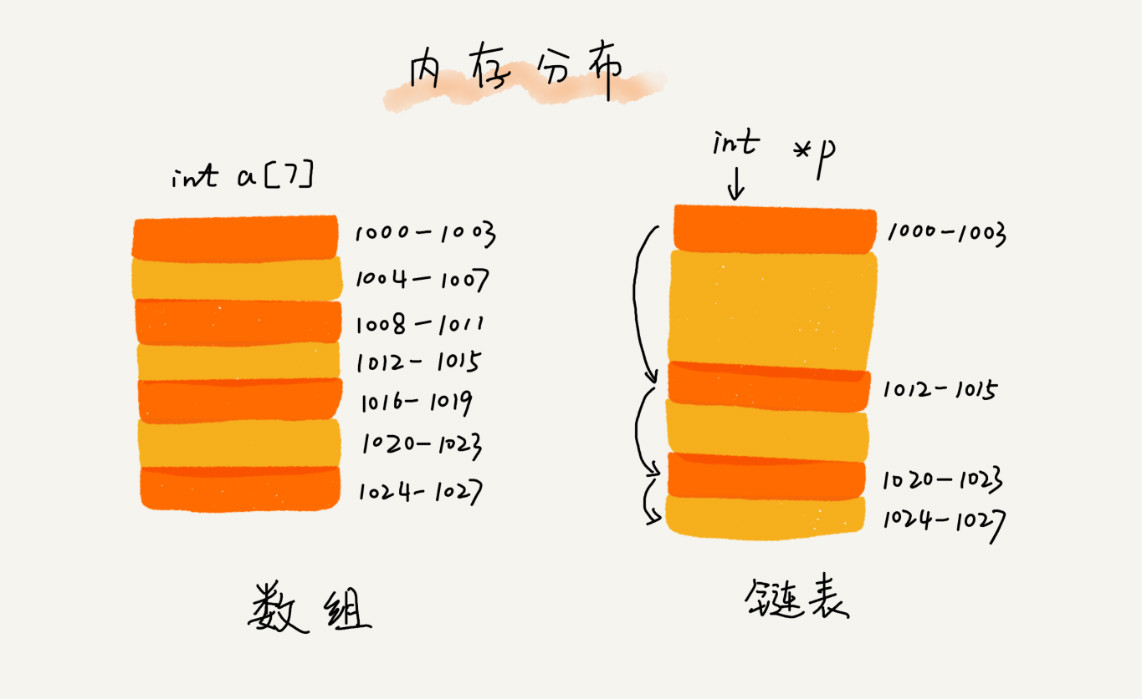
链表的特点
链表由指针和节点组成,链表的种类有很多,比较常见的有单链表、双向链表、循环链表等。链表与数组不同,链表在内存中的存储占用零散的非连续的内存块,而数组则是连续的内存块空间。链表通过指针把分散在内存中的结点连接起来。 当想要查找链表中的某一个结点数据时需要从头开始查找直到找到目标数据位置,因此链表随机访问的时间复杂度为O(n)。
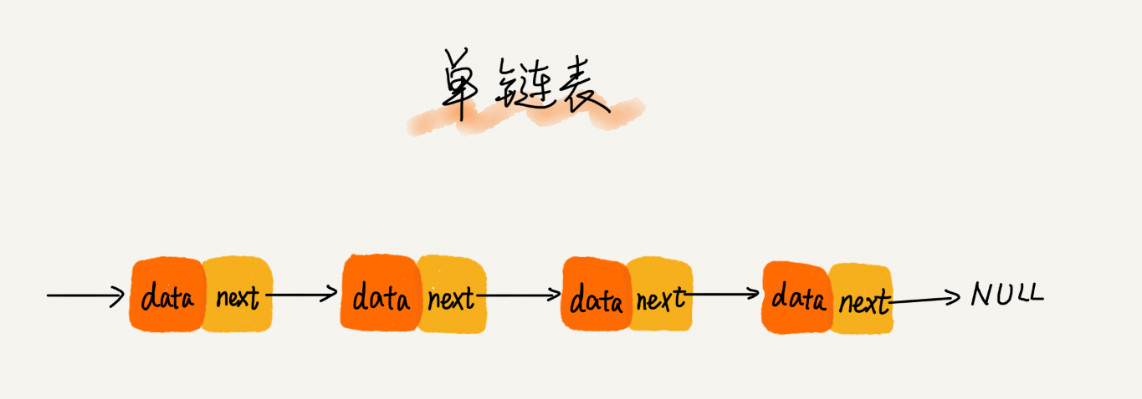
单链表
指向下一个结点的指针叫做后继指针next,链表中有两个特殊的结点“第一个结点”和“最后一个结点”,第一个结点叫做头结点,最后一个结点叫做尾结点。头结点记录链表的基地址,尾结点的next指向null。
单链表很简单就是指针从头结点一个一个的指到尾结点。
附上自己写的一个单链表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
| public class SingleLinkedList<T> {
private int size = 0;
private Node head;
private class Node{
private T data;
private Node next;
private Node(T data, Node next) {
this.data = data;
this.next = next;
}
@Override
public String toString() {
return "Node{" +
"data=" + data +
", next=" + next +
'}';
}
}
public SingleLinkedList() {
this.size = 0;
this.head = new Node(null,null);
}
public void add(T t){
Node current = head;
while (current.next!=null){
current = current.next;
}
current.next = new Node(t,null);
this.size ++;
}
public Node get(T t){
Node current = head;
for(int i=0;i<size;i++){
if(current.data!=null && current.data.equals(t)){
return current;
}else {
current = current.next;
}
}
return null;
}
public int size(){
return this.size;
}
public void remove(T t){
Node current = head;
for(int i=0;i<size;i++){
if(current.next.data.equals(t)){
current.next =current.next.next;
}else {
current = current.next;
}
}
}
public void inverse(){
Node prevNode = null;
Node current = head.next;
Node next = null;
while(current!=null){
prevNode = current.next;
current.next = next;
next = current;
current = prevNode;
}
head.next = next;
}
@Override
public String toString() {
return "SingleLinkedList{" +
"size=" + size +
", head=" + head +
'}';
}
}
|
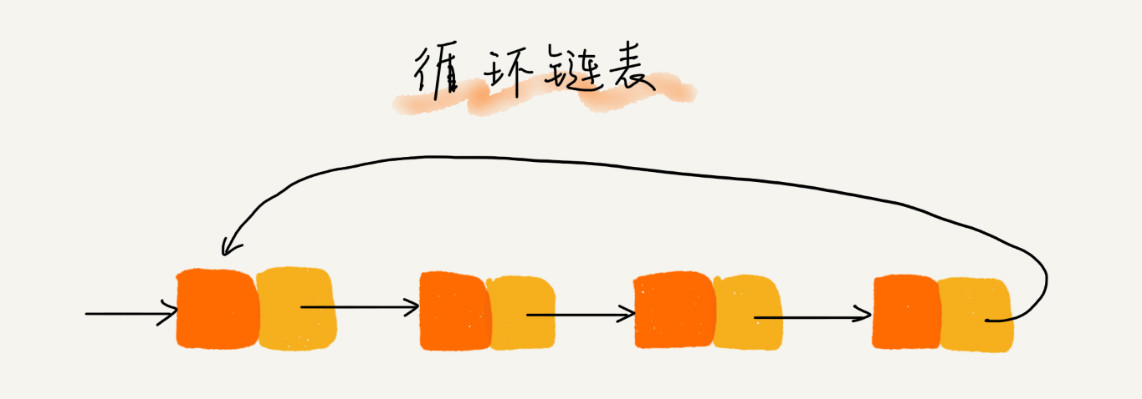
循环链表
循环链表是一种特殊的单链表,循环链表的尾结点指针指向该链表的头结点,使链表首尾相连方便在尾结点直接找到头结点。
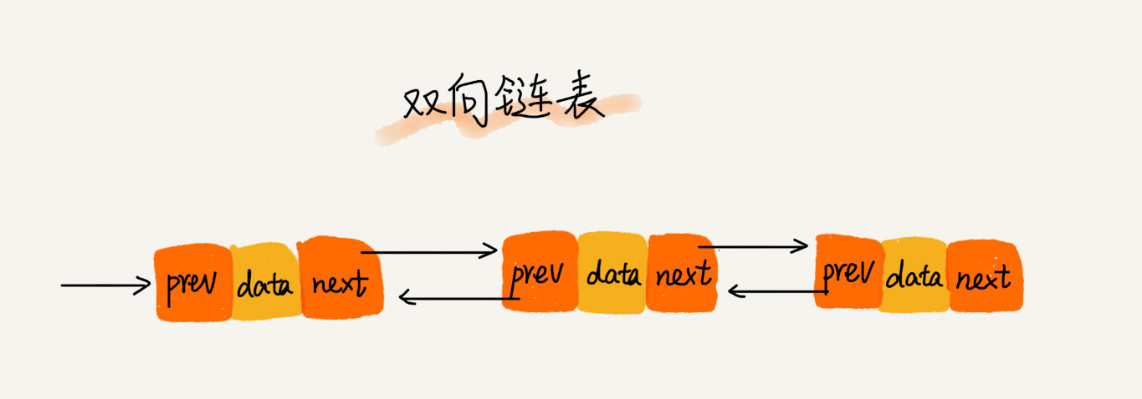
双向链表
双向链表和单链表相比增加了一个前驱指针prev指向当前结点的前一个结点。因此双向链表可以非常快地找到前驱结点。然而双向列表需要在内存中存储前驱指针prev因此相比单链表会占用更多的内存空间。
链表和数组比较
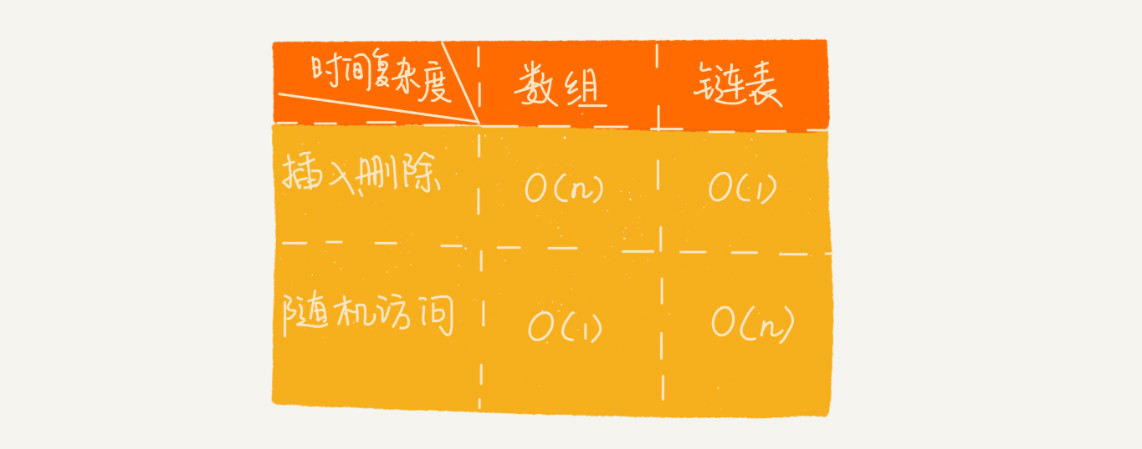
文中图片摘自 极客时间-数据结构与算法之美-第6节 链表上